분산 시스템 PK 전략 - UUIDv7은 과연 AUTO_INCREMENT를 대체할 수 있는가? 성능은?
Intro
현대적인 백엔드 아키텍처를 설계할 때, Primary Key(PK) 선택은 시스템의 확장성과 성능을 결정짓는 가장 기초적이면서도 중요한 의사결정입니다. 과거에는 AUTO_INCREMENT가 표준이었으나, MSA(Microservices Architecture)와 분산 시스템이 주류가 되면서 UUID의 필요성이 대두되었습니다.
특히 최근 등장한 UUIDv7은 시간 기반의 순차성을 보장한다는 점에서 “성능과 분산 처리라는 두 마리 토끼를 모두 잡을 수 있을 것”이라는 기대를 모으고 있습니다. 과연 실제 운영 환경에서도 그 기대만큼의 퍼포먼스를 보여줄까요? 이번에는 500만 건의 대규모 데이터 벤치마크 결과를 바탕으로, AUTO_INCREMENT와 UUIDv7 사이의 기술적 격차와 트레이드오프를 심층적으로 공유하려 합니다.
1. 문제 상황: 확장성과 성능 사이의 딜레마
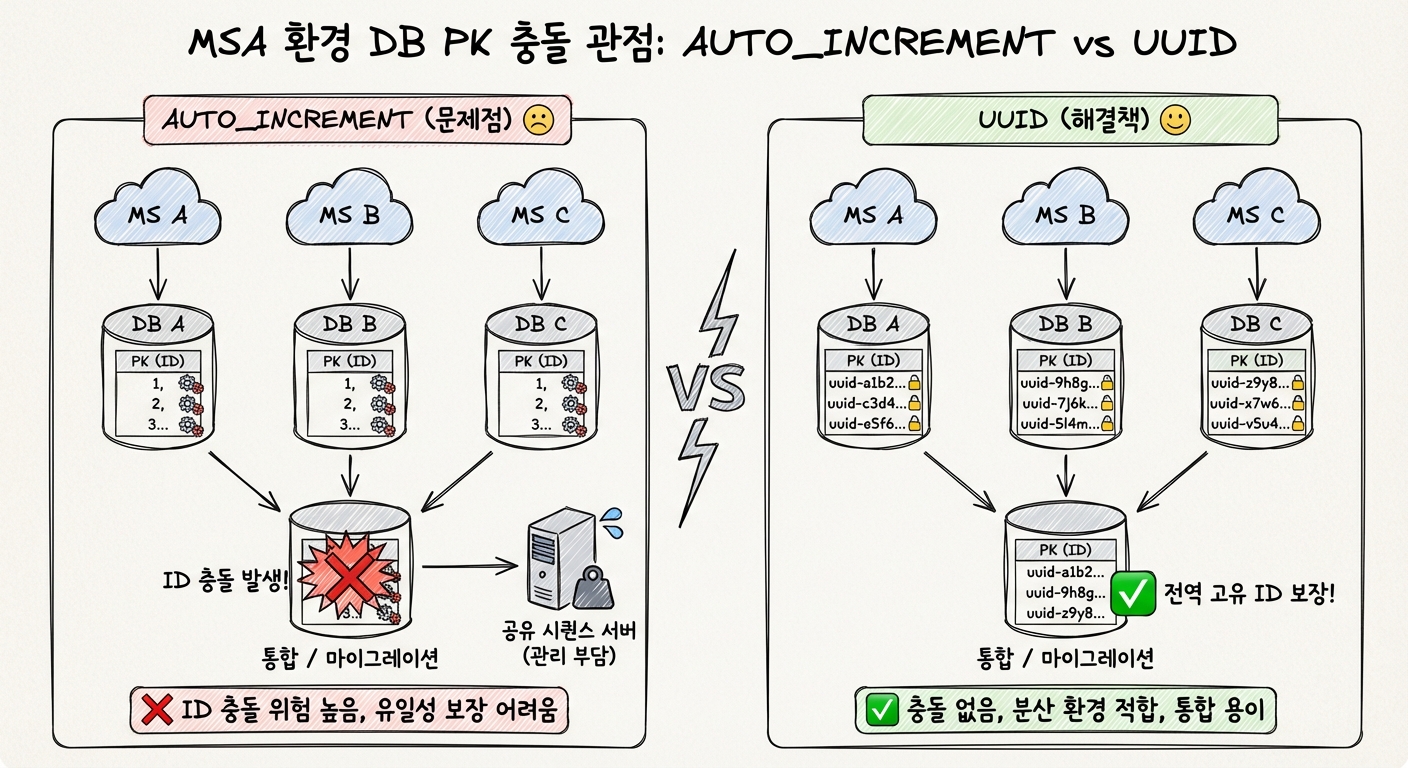
서비스 규모가 커지며 MSA(Microservices Architecture) 환경으로 전환하면, 각 서비스는 자신만의 데이터베이스를 가집니다. 이때 AUTO_INCREMENT를 사용하면 서비스 간 데이터 통합이나 마이그레이션 시 ID 충돌이 발생할 위험이 크며, 전역적으로 고유한 ID를 생성하기 위해 별도의 공유 시퀀스 서버를 운영해야 하는 관리 부담이 생깁니다.
반면, UUIDv4는 어디서든 고유한 ID를 생성할 수 있어 MSA에 적합하지만, 완전한 랜덤성으로 인해 B-Tree 인덱스의 리프 노드를 무작위로 타격하며 성능을 심각하게 저하시킵니다. UUIDv7은 이 문제를 해결하기 위해 타임스탬프를 상위 비트에 배치하여 ‘순차적 삽입’이 가능하도록 설계되었습니다. 하지만 여전히 물리적 크기는 16 bytes로, 8 bytes인 BIGINT보다 두 배나 큽니다.
“둘 다 순차적이라면, 과연 데이터 크기 차이가 실무에서 유의미한 성능 저하를 일으킬 것인가?” 라는 의문에서 본 테스트를 시작했습니다.
2. 원인 분석: 프로토콜과 인덱스 아키텍처의 관점
2.1 데이터 타입의 물리적 한계
MySQL의 InnoDB 스토리지 엔진은 데이터를 16KB 단위의 Page로 관리합니다. PK의 크기가 커진다는 것은 단순히 디스크 용량을 더 차지한다는 뜻을 넘어, 메모리 효율성(Buffer Pool Efficiency)에 직접적인 영향을 미칩니다.
BIGINT (8 bytes): 포인터와 메타데이터를 포함해도 한 페이지에 더 많은 인덱스 엔트리를 담을 수 있습니다.
BINARY(16) (16 bytes): 페이지 내 엔트리 밀도가 낮아지며, 이는 곧
B-Tree의 깊이(Depth)가 깊어질 가능성을 높이고, 같은 양의 데이터를 조회할 때 더 많은 I/O를 유발합니다.
2.2 순차성의 질적 차이
AUTO_INCREMENT는 완벽한 단조 증가(Monotonic Increasing)를 보장합니다. 반면 UUIDv7은 밀리초(ms) 단위의 타임스탬프 뒤에 랜덤 비트가 붙습니다. 아주 짧은 찰나에 대량의 삽입이 일어날 경우, 동일 밀리초 내에서의 정렬 순서는 보장되지 않아 미세한 ‘지그재그’ 삽입이 발생하며, 이것이 누적되어 페이지 분할(Page Split) 및 인덱스 파편화로 이어집니다.
💡 Monotonic Increasing이란?
데이터가 추가될 때 항상 이전 값보다 큰 값이 생성되는 성질을 의미합니다. 이는 B-Tree 인덱스에서 새로운 데이터를 항상 리프 노드의 맨 끝(Right-most)에만 추가하게 하여, 중간 노드의 페이지 분할(Page Split)을 방지하고 쓰기 성능을 극대화하는 핵심 요소입니다. UUIDv7은 ‘시간 순’으로는 단조 증가에 가깝지만, 동일 시간대 내의 ‘무작위성’ 때문에 엄격한 의미의 단조 증가는 만족하지 못합니다.
[!CAUTION] 라이브러리별 구현 차이 주의 UUIDv7을 생성하는 라이브러리마다 동일 밀리초 내에서 순차성을 보장(Counter 사용 등)하는 방식이 다릅니다. 완벽한 단조 증가가 필요한 환경이라면 사용하는 라이브러리가 해당 기능을 지원하는지 반드시 확인해야 합니다.
3. 후보군 정리 및 성능 벤치마크
| 구분 | AUTO_INCREMENT (BIGINT) | UUIDv7 (BINARY(16)) |
|---|---|---|
| 장점 | 최고 성능, 저장 공간 최적화, 인덱스 효율성 | 분산 생성 가능, ID 예측 불가(보안), 확장성 |
| 단점 | 분산 환경에서 충돌 위험, 비즈니스 로직 노출 | 스토리지 비용 증가, CPU 오버헤드 |
3.1 벤치마크 결과 데이터 (실측치)
실제 테스트는 NestJS와 Prisma 환경에서 $executeRawUnsafe를 통해 순수 DB 실행 시간만을 정밀하게 측정했습니다.
| 테스트 항목 | AUTO_INCREMENT (BIGINT) | UUIDv7 (BINARY(16)) | 성능 차이 |
|---|---|---|---|
| 대량 적재 (5M건) | 33.93초 (147k ops/s) | 45.29초 (110k ops/s) | AUTO 약 33.5% 우세 |
| 단건 삽입 (50k건) | 50.83초 | 56.42초 | AUTO 약 11% 우세 |
| 동시 부하 (20 Workers) | 7.46초 (StdDev 3.75ms) | 8.18초 (StdDev 15.9ms) | AUTO 약 9.6% 우세 |
| 인덱스 크기 (5M건 기준) | 65.59 MB | 103.69 MB | UUIDv7이 58% 더 큼 |
A. 대량 적재 (5,000,000건 Batch Insert)
AUTO_INCREMENT: 33.93초 (약 147,358 ops/sec)
UUIDv7: 45.29초 (약 110,391 ops/sec)
결과:
AUTO_INCREMENT가 약 33.5% 빠름. 대량 적재 시 물리적으로 더 잦은 페이지 분할(Page Split)이 발생하며 성능 격차를 크게 벌렸습니다.
B. 단건 삽입 (50,000건 개별 요청)
AUTO_INCREMENT: 50.83초
UUIDv7: 56.42초
결과: 약 11% 차이. 네트워크 오버헤드와 트랜잭션 처리 시간이 포함되면서 PK 자체의 성능 차이는 희석되었습니다.
C. 동시성 부하 테스트 (50,000건, 20 Workers)
AUTO_INCREMENT: 7.46초 (StdDev: 3.75ms)
UUIDv7: 8.18초 (StdDev: 15.9ms)
결과: 약 9.6% 차이. 다만
UUIDv7의 표준편차가 4배 이상 높았습니다. 이는 동시 부하 시 인덱스 경합이 간헐적으로 지연을 유발함을 뜻합니다.
3.2 저장 공간 효율성
Index Size:
AUTO(65.59MB) vsUUIDv7(103.69MB) → UUIDv7이 58% 더 큼.인덱스 크기의 증가는 메모리에 상주할 수 있는 인덱스 양을 줄여, 장기적인 운영 관점에서 캐시 히트율(Cache Hit Rate) 저하의 근본 원인이 됩니다.
4. 해결 전략: 도메인과 부하에 따른 PK 선택
선택지는 명확했습니다. 성능이 최우선이라면 AUTO_INCREMENT를, 확장성과 분산 처리가 최우선이라면 UUIDv7을 선택해야 합니다.
전략 1: 단일 DB 기반의 고성능 트래픽 처리
방법: PK는
BIGINT(AUTO_INCREMENT)를 유지합니다.이유: 초당 수만 건의 쓰기가 발생하는 로그성 데이터나 대규모 주문 처리 시스템에서 30%의 성능 차이는 서버 자원 30% 절감과 직결됩니다.
전략 2: 분산 마이크로서비스(MSA) 및 보안 중시 시스템
방법: PK로
BINARY(16)타입의UUIDv7을 사용합니다.이유: 10~15%의 성능 패널티는 시스템 확장성으로 충분히 상쇄 가능합니다. 특히 클라이언트가 ID를 직접 생성하여 서버에 전송하는 패턴에서 멱등성(Idempotency) 보장에 매우 유리합니다.
5. 결론
벤치마크 결과, AUTO_INCREMENT는 성능과 효율성 측면에서 압도적인 우위를 점하고 있습니다. 하지만 UUIDv7은 기존 UUIDv4의 치명적인 단점이었던 인덱스 파편화 문제를 극복하며, 분산 환경에서 실무에 적합한 퍼포먼스를 보여주었습니다.
결국 기술 선택의 핵심은 비즈니스의 스케일과 아키텍처에 있습니다.
- MSA 환경의 충돌 해결: 여러 서비스 노드에서 독립적으로 ID를 생성해도 중복 위험이 없는
UUIDv7은 중앙화된 ID 생성기 없이도 충돌 문제를 근본적으로 해결합니다. - 성능과 확장성의 타협: 약 10~30%의 성능 오버헤드가 발생하지만, 이는 시간 기반 정렬(Time-ordered) 특성을 활용한 인덱스 최적화를 통해
UUIDv4대비 비약적인 성능 향상을 이뤄낸 결과입니다.
“성능을 위해 충돌 위험을 감수할 것인가, 확장성을 위해 약간의 리소스를 더 쓸 것인가?” 라는 질문에서, UUIDv7은 분산 시스템의 복잡도를 낮추면서도 납득 가능한 수준의 성능을 제공하는 가장 현실적인 정답이 될 것입니다.