Long-Lived Transactions의 한계와 Saga
Intro
단일 DB에서 복잡한 다단계 비즈니스 흐름을 ACID 트랜잭션으로 구현하다 보면, 외부 API 호출이 없더라도 순수 DB 작업만으로 트랜잭션이 길어지면서 다양한 문제가 발생합니다. 락 경합, 타임아웃, 동시성 이슈 등으로 인해 시스템 안정성이 흔들리고, 결국 확장성에 한계를 느끼게 되는 경우가 많습니다.
이번 글에서는 1987년 Sagas 논문에서 제안된 개념을 살펴보고, 장기 실행 트랜잭션의 문제를 해결하려는 배경과 접근 방식을 정리해 보았습니다. 실제로 단일 DB 환경에서 장기 흐름을 고민하거나 MSA 확장을 준비 중인 분들에게 실질적인 도움이 되기를 바랍니다.
1. Long-Lived Transactions (LLT)란?
실무에서 LLT가 발생하는 형태
LLT는 단순히 비즈니스 프로세스가 길어지는 것이 아니라, 하나의 DB 트랜잭션(락)이 비정상적으로 오랫동안 유지되는 상황을 말합니다. 사용자의 대기 시간은 트랜잭션 외부에서 처리해야 하므로 LLT의 직접적인 원인이 되지 않습니다.
LLT는 아래와 같이 트랜잭션 범위 내에서 처리량이 많거나 대기가 발생하는 경우에 나타납니다:
대량 데이터 배치 처리
수십만 건 이상의 레코드를 단일 트랜잭션으로UPDATE또는INSERT실행
→ Lock 유지 시간이 수분 이상 소요되며 다른 트랜잭션 대기 발생트랜잭션 내 외부 시스템 동기 호출
DB 트랜잭션 내부에서 외부 API(결제 승인, 타 시스템 연동)를 동기적으로 호출하여 대기
→ 네트워크 지연 시간만큼 DB 리소스(Lock, Connection) 점유복잡한 연산 포함 트랜잭션
대규모 데이터 조회 후 복잡한 비즈니스 로직을 수행하고 다시 업데이트하는 과정을 원자적으로 처리
→ CPU 연산 및 Lock 경합으로 인해 트랜잭션 시간 장기화
이런 흐름은 비즈니스적으로 원자성이 필요해 보이지만, DBMS 입장에서는 장기간 Lock을 점유하여 시스템 전체의 동시성을 파괴합니다.
2. LLT가 왜 문제인가?
근본 원인과 운영 충격
장기 Lock 유지 → 동시성 붕괴 → 피크 타임에 치명적
| 문제 유형 | 주요 증상 | 근본 원인 | 실무 영향 |
|---|---|---|---|
| Lock 경합 | 대기 큐 급증 | 장기 Exclusive/Shared Lock | 처리량 급락 |
| Concurrency 붕괴 | 동시 트랜잭션 제한 초과 | Lock Manager 자원 고갈 | 타임아웃 폭증 |
| Deadlock 발생 | Deadlock 알람 빈발 | 장기 Lock 간 순환 대기 | 자동 Rollback → 데이터 불일치 위험 |
| 자원 소진 | Connection Pool 고갈 | Undo Log 장기 유지 | 서비스 불안정 / 다운 |
3. Saga 패턴이란?
원 논문 기반 핵심 원리
1987년 논문 Sagas에서 제안된 Saga는 장기 Lock 문제를 근본적으로 회피하는 설계입니다.
핵심 정의 A saga is a sequence of local transactions ( T_1, T_2, \dots, T_n ) that can be interleaved with other transactions. Either all complete, or compensating transactions ( C_1, C_2, \dots, C_{i-1} ) execute to undo partial effects.
핵심 원리 4가지
전체 비즈니스 프로세스를 여러 단계로 분해하여, 각 단계를 독립적인 로컬 트랜잭션(local transaction)으로 처리합니다. 각각의 단계는 자체적으로 데이터베이스의 트랜잭션으로 감싸지며, 이 단계가 끝날 때마다 바로 Commit이 이뤄집니다. 따라서 각 단계마다 장기 Lock이 유지되지 않고, 빠르게 커밋할 수 있어 시스템 리소스 소모를 크게 줄일 수 있습니다.
여러 Saga 인스턴스가 동시에 실행될 수 있으며, 서로 다른 Saga의 단계들이 인터리빙(교차 수행, interleaving)될 수 있도록 허용합니다. 즉, 어떤 Saga의 1단계와 다른 Saga의 1~3단계가 겹쳐서 실행되는 식으로, 작업 흐름이 직렬화되지 않고 병렬로 처리됩니다. 이를 통해 시스템 전체의 동시성을 극대화하고, 처리량도 높일 수 있습니다.
만약 중간에 단계가 실패하면, Saga 패턴은 보상 트랜잭션(compensating transaction)을 이용하여 실패 시점까지 수행된 작업을 역순(reverse order)으로 하나씩 취소(rollback)합니다. 즉, 일반 트랜잭션의 atomic rollback 대신, 이제까지 커밋된 로컬 트랜잭션들을 사용자가 정의한 보상 작업으로 논리적으로 되돌리는 방식입니다. 이 덕분에 전통적인 rollback이 불가능한 분산 환경에서도 일관성을 일정 수준 보장할 수 있습니다.
트랜잭션 Lock(락)은 오직 각 로컬 트랜잭션의 단기 수행 시간에만 적용됩니다. Saga 전체가 끝날 때까지 긴 기간 Lock을 유지하지 않으므로, 리소스 고갈이나 동시성 붕괴 같은 전통적인 장기 트랜잭션의 문제를 최소화할 수 있습니다. 이로써 장기적으로 시스템의 안정성과 확장성을 확보할 수 있습니다.
ACID 속성 변화
| ACID | Saga에서의 변화 | 설명 |
|---|---|---|
| Atomicity | Semantic Atomicity로 대체 | 보상 로직이 전체 성공/실패 보장 |
| Consistency | 유지 | 각 로컬 트랜잭션에서 비즈니스 규칙 검증 |
| Isolation | 포기 | 중간 상태 노출 |
| Durability | 유지 | 각 로컬 트랜잭션 커밋 후 영구 저장 |
핵심 트레이드오프 = Isolation 포기 → 다음 섹션에서 문제와 해결책 자세히 다룹니다.
중요 전제 비즈니스 관점의 원자성 단위는 그대로 유지해야 합니다. 책임이 DBMS → 애플리케이션(Saga 상태 관리)으로 이동할 뿐입니다.
4. Saga의 트레이드오프: Isolation 손실 문제
문제의 본질
Saga 패턴에서는 각 로컬 트랜잭션이 작업을 마칠 때마다 즉시 커밋합니다. 전체 비즈니스 프로세스가 완전히 끝나지 않았음에도 불구하고, 개별 단계(재고 차감, 금액 이체 등)의 결과가 데이터베이스에 반영되어 다른 트랜잭션이나 외부 시스템에 중간 상태(intermediate state)로 노출됩니다.
왜 문제가 되는가?
한 Saga 인스턴스가 단계별로 작업을 완료해가는 동안, 전체 Saga가 최종 성공하거나 보상 트랜잭션으로 롤백하기 전이라도 이미 수행된 일부 변경사항이 다른 사용자의 트랜잭션이나 동시에 진행 중인 다른 Saga 인스턴스에 그대로 보여질 수 있습니다.
이런 중간 상태 노출은 전통적인 ACID 트랜잭션(특히 Isolation 보장)과 달리, 업데이트의 일관적 완결이 보장되지 않습니다. 그 결과 잘못된 근거로 의사결정을 하거나 논리적 오류를 야기할 수 있는 위험이 존재합니다.
문제 예시
1
2
3
4
1. Saga A: 재고 차감 성공 → 결제 대기 중
2. Saga B: 차감된 재고를 조회 → 재고 부족으로 잘못된 판단
3. Saga A: 결제 실패 → 재고 복구(보상 트랜잭션)
4. 결과: Saga B의 결정이 무효화됨
주요 해결 기법
| 기법 | 설명 | 적용 방법 |
|---|---|---|
| Semantic Lock | 데이터에 “처리 중” 상태 필드 추가 | 다른 Saga가 상태 확인 후 진행 여부 결정 |
| 낙관적 락 | Version 컬럼으로 충돌 감지 | 변경 시 버전 확인하여 동시성 제어 |
| Commutative Update | 순서 무관 연산 설계 | quantity = quantity - 10 같은 교환 가능한 연산 사용 |
| 비즈니스 수준 검증 | 보상 전 다른 Saga 영향 확인 | 필요 시 연쇄 보상 트랜잭션 실행 |
실제 사례 포인트 차감 Saga 중 조회 시 잘못된 잔액이 노출되는 문제가 발생했으나, Semantic Lock 도입 후 해결되었습니다.
5. 복구 전략: Backward vs Forward Recovery
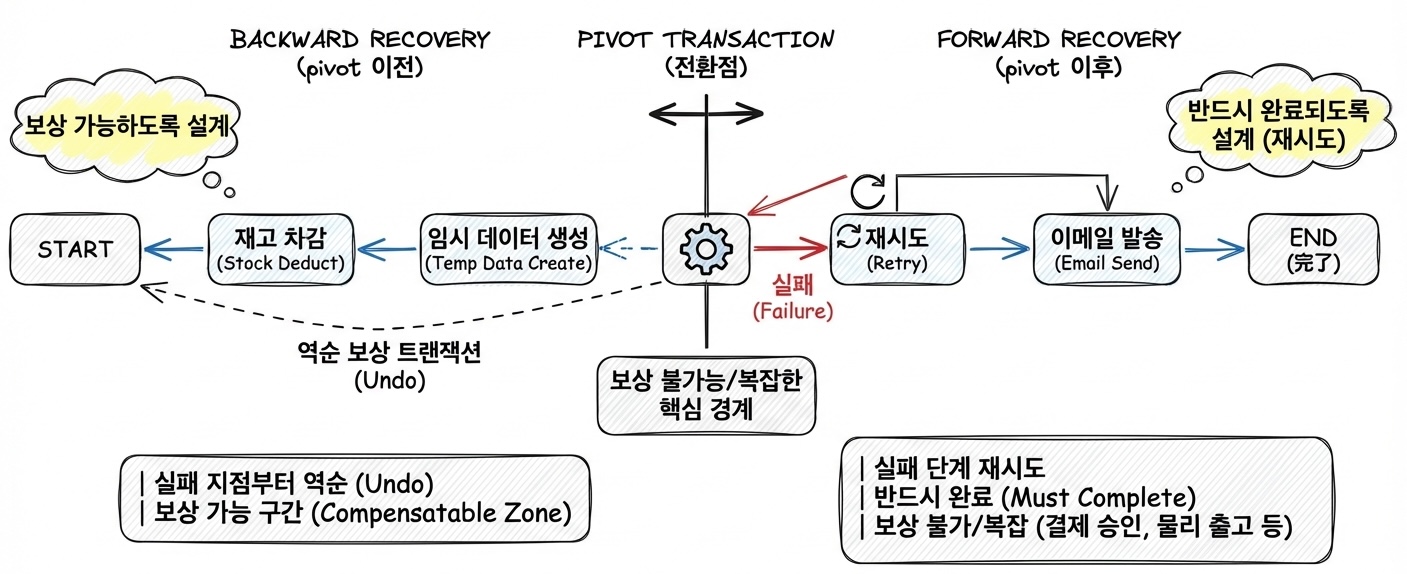
| 전략 | 설명 | 적용 시점 |
|---|---|---|
| Backward Recovery | 실패 지점부터 역순 보상 | Pivot 이전 |
| Forward Recovery | 실패 단계 재시도하여 완료 | Pivot 이후 |
Pivot Transaction란 Saga 복구 전략에서 ‘전환점(pivot point)’이 되는 중요한 단계입니다. Saga 패턴에서는 여러 개의 로컬 트랜잭션이 순차적으로 실행되는데, 이 중 일부는 실패 시 이전 상태로 완전히 되돌릴 수 있는(즉, 보상 트랜잭션이 가능한) 작업이고, 반면 어떤 단계들은 보상 자체가 불가능하거나 대단히 복잡한 작업일 수 있습니다. ‘Pivot Transaction’이란 이 두 구간의 경계에 해당하며,
- 이 전(이전 단계)까지는 만약 문제가 생기면 backward recovery—즉, 이미 실행된 작업들을 차례차례 역순(undo)으로 원상복구(보상 트랜잭션)할 수 있도록 설계합니다.
- 이 Pivot Transaction을 기점으로, 그 이후부터는 보상이 현실적으로 어렵기 때문에 forward recovery, 즉 작업을 반드시 끝낼 때까지(재시도 등으로) 성공시켜야 하는 구간이 됩니다.
예를 들어, 결제 서비스 Saga의 경우 결제 승인(혹은 실제 금전 거래)이 Pivot이 될 수 있습니다. 그 전 단계(예: 재고 차감, 임시 데이터 생성 등)는 실패 시 원상복구가 가능하지만, 실제 돈이 송금되는 결제 승인이 일어난 이후에는 보상이 불가하기 때문에 반드시 최종 완료(Forward Recovery)로 설계해야 합니다.
따라서 Pivot Transaction의 정확한 식별과 그 전후의 로직 구조(보상 vs. 재처리)는 Saga 설계에서 매우 중요한 핵심 포인트입니다.
- Pivot 이전: 모두 보상 가능하도록 설계
- Pivot 이후: 재시도로 반드시 완료되도록 설계
- 보상 불가능 예시: 이메일 발송, 결제 승인, 물리 출고 등
6. 실무 적용: LLT → Saga 전환 전략
모놀리스 + 단일 DB(ACID) 환경에서 LLT를 Saga로 바꾸는 핵심은 “DB 트랜잭션을 길게 잡지 않고, 짧은 로컬 트랜잭션 여러 개로 나눠서 상태로 이어 붙이는 것”입니다.
전환 판단 체크포인트(의사결정 트리)
- LLT 유지가 합리적인 경우
- 한 번의 트랜잭션으로 수 초 이내 종료되고(락 점유가 짧고), 외부 대기/재시도 요구가 거의 없음
- 실패 시 전부 롤백하는 것이 도메인 요구와 정확히 일치(“부분 성공” 자체가 의미 없음)
- Saga 후보가 되는 경우(하나라도 해당하면 전환 고려)
- 트랜잭션 안에 대기 시간이 섞임(사용자 입력/승인 대기, 배치 처리 대기, 재시도 포함 등)
- 같은 레코드/집합을 오래 잡아 락 경합·타임아웃·데드락이 운영 이슈로 번짐
- “실패하면 전체 롤백”보다 부분 성공 후 복구(보상/재시도)가 더 현실적
- 단계별로 결과를 남기고 재개(resume)해야 장애 복구가 가능함
추천 방식: Orchestration(단일 애플리케이션 내부에서 중앙 제어) 중앙에서 상태와 흐름을 관리하면 가시성(현재 어디까지 왔는지)과 복구(재시도/보상/수동개입)가 훨씬 쉬워집니다.
상태 저장(최소 구성)
- Saga 인스턴스(전체 상태): saga_id, type, correlation_id(업무키), status, current_step, payload(필요한 스냅샷)
- 단계 이력(감사·재시도 기반): step, attempt, 실행/보상 여부, 결과(성공/실패/스킵), 시점, 에러 요약
트레이드오프(“고립성 포기”)와 완화책
- 문제: 중간 상태가 DB에 커밋되므로, 다른 기능이 “진행 중” 데이터를 볼 수 있음
- 완화: 상태값(예: PROCESSING/CONFIRMED/CANCELLED)로 읽기 정책을 명시하고, 진행 중에는 의미 있는 동작만 허용(= semantic lock)
- 문제: 중복 실행 시 부작용이 누적될 수 있음
- 완화: 단계 이력/업무키 기반으로 멱등성 보장(이미 완료된 단계면 재실행 대신 “이미 처리됨”으로 통과)
- 문제: 보상 로직이 복잡하거나 불가능한 단계가 있음
- 완화: Pivot을 기준으로 이전은 보상 가능하게 설계, 이후는 반드시 완료(Forward recovery)되도록 재시도/운영 개입 경로 준비
실패/보상 시나리오 예시(일반화)
- 시나리오 A: 보상 가능한 단계에서 실패
- 1단계(자원 “예약/표시”) 성공 → 2단계 실패
- 결과: 1단계 보상(예약 해제/표시 취소) 후 Saga 종료(FAILED/COMPENSATED)
- 시나리오 B: Pivot 이후 실패(보상이 사실상 불가)
- Pivot(되돌리기 어려운 확정 단계) 성공 → 후속 정리 단계 실패
- 결과: 보상 대신 재시도로 끝까지 완료(FORWARD RECOVERY). 운영 관점에서는 “완료될 때까지 달라붙는 작업”으로 취급
- 시나리오 C: 보상도 실패
- 2단계 실패로 1단계 보상을 시도했지만 보상 자체가 실패(락/경합/일시 오류 등)
- 결과: 보상 재시도(백오프/횟수 제한) + 그래도 안 되면 수동 처리 대기로 전환(상태·이력에 원인과 위치가 남아야 함)
요약하면, LLT의 장점(강한 원자성)을 그대로 유지하려고 애쓰기보다 짧은 트랜잭션 + 상태 기반 복구로 운영 리스크(락/타임아웃/장애 복구 난이도)를 낮추는 방향이 실무에서 안정적입니다.
7. 1987년 Saga와 현대에서 말하는 “MSA Saga”의 공통점과 차이
요즘 “Saga”라는 단어는 주로 MSA 맥락에서 자주 등장하지만, 뿌리는 1987년 논문 Sagas 에서 제안한 모델과 연결됩니다. 다만 같은 이름을 쓰더라도 전제(문제/실패 모델)가 달라 오해가 생기곤 합니다.
공통점(핵심 아이디어는 같다)
- 긴 비즈니스 흐름을 여러 개의 짧은 트랜잭션으로 분해한다
- 각 단계는 커밋되고, 실패 시 보상 트랜잭션(논리적 취소/undo) 으로 되돌린다
- DB의 “진짜 원자성” 대신, 애플리케이션 수준 원자성(application-level atomicity) 을 목표로 한다
- Pivot을 기준으로 Backward/Forward recovery를 나눠 설계한다
- 재시도/중복 실행을 고려한 멱등성이 사실상 필수다
차이점(전제가 달라서 설계 포인트가 달라진다)
- 1987년 Saga: 주로 단일 DB 내부에서 LLT가 만드는 락/동시성 문제를 다루며, “서브트랜잭션 + 보상”을 DB 트랜잭션 모델 관점에서 설명한다
- 현대의 ‘MSA Saga’: 서비스/DB 경계를 넘는 분산 트랜잭션의 대안으로 쓰이며, 네트워크/전달/중복/순서 같은 불확실성이 설계의 중심 제약이 된다
이 글은 단일 DB에서 LLT를 Saga로 전환하는 관점이라, 1987년 정의에 더 가깝습니다. 반면 현대 MSA에서 강조되는 “전달 신뢰성” 이슈는 상대적으로 단순해지고, 대신 상태 저장·재개·보상/재시도 정책이 주된 실무 포인트가 됩니다.
✅ 결론
복잡한 도메인 로직과 정책, 그리고 대량의 insert 작업으로 인해 하나의 DB 트랜잭션이 너무 길어지는 상황에 직면했습니다.
처리 속도가 충분히 빠른 경우에는 단일 트랜잭션으로 묶는 것이 가장 이상적입니다. 하지만 요청 처리 시간이 분 단위로 늘어나면서 대량의 요청이 몰릴 때 락 경합, 타임아웃, 동시성 이슈 등 여러 문제가 발생하곤 했습니다.
이러한 문제를 해결하기 위해 자료를 찾다가 1987년 Sagas 논문을 알게 되었고, 공부한 내용을 정리한 이 글이 비슷한 고민을 하시는 분들께 도움이 되었으면 합니다.