SIGNOZ - 보안 제약 환경에서의 OpenTelemetry 기반 자체 모니터링 시스템 구축하기
Intro
보안 제약 환경에서 OpenTelemetry를 기반으로 자체 로깅 및 계측 시스템을 구축한 경험을 공유하고자 합니다. 클라우드 서비스 제공자(CSP) 환경에서 보안 규정을 준수하면서 효과적인 시스템 모니터링 체계를 만드는 것은 쉽지 않은 과제입니다. 이번 글에서는 제가 겪었던 문제 상황부터 솔루션 선택, 구축 과정, 그리고 운영까지 도입 과정을 상세히 다루어보겠습니다.
기존 환경 분석
이미 프로젝트에서 Zero Code Instrumentation 방식을 적용하고 있었습니다. Datadog Agent를 사용하여 OTLP로 Trace를 수집하고, Datadog을 통해 모니터링을 수행했습니다. OpenTelemetry를 도입했던 이유는 언제든 Datadog을 다른 솔루션으로 교체할 수 있도록 준비하기 위함이었고, 이번 CSP 환경에서 작업하면서 이러한 준비가 빛을 발휘하게 되었습니다.
요구사항 분석
새로운 환경에서 구축해야 할 모니터링 시스템의 주요 요구사항은 다음과 같습니다:
- Trace 시스템 구축: 분산 트랜잭션 추적
- 인프라 모니터링: CPU, 메모리, 네트워크 등
- 데이터베이스 Metrics 수집: 쿼리 성능, 연결 상태 등
- 로깅 시스템 구축: 애플리케이션 로그, 시스템 로그
- Trace와 Logging 통합: 로그와 트레이스 연관 분석
- Zero Code Instrumentation 유지: 코드 변경 없이 즉시 도입
Trace와 Logging 통합의 중요성
분산 시스템에서는 하나의 요청이 여러 마이크로서비스를 거치며 처리되는 경우가 많습니다. 이때, 특정 요청의 전체 흐름을 파악하고 문제 발생 지점을 정확히 식별하려면 Trace 정보와 로그 정보를 통합적으로 분석하는 것이 필수적입니다. 통합된 관점에서 로그와 트레이스를 확인할 수 있다면, 문제 발생 시 근본 원인 분석이 훨씬 수월해지고 디버깅 시간을 크게 단축할 수 있습니다.
솔루션 검토 및 비교 분석
후보 솔루션 개요
자체 로깅 및 계측 시스템 구축을 위해 검토한 오픈소스 솔루션은 다음과 같습니다.
- Sentry: 에러 및 예외 추적에 특화, 성능 모니터링 기능도 제공
- SigNoz: OpenTelemetry 네이티브 지원 강조, Trace, Metrics, Logs 통합 제공
- LGTM 스택 (Loki, Grafana, Tempo, Mimir): 로깅, 시각화, 트레이싱, Metrics를 담당하는 컴포넌트 조합
세 솔루션 모두 Kubernetes나 Docker Compose로 설치 가이드를 제공하며, 비교적 빠르게 도입 가능하다고 판단했습니다.
평가 기준
솔루션을 다음 기준으로 비교 분석했습니다.
- OpenTelemetry 호환성: 기존 OpenTelemetry 계측과의 통합 용이성
- Self-hosting 가능성: 보안 제약 환경 내 자체 구축 및 운영 가능성
- 확장성 (성능 및 데이터 저장): 데이터 증가에 따른 확장성과 운영 편의성
솔루션 비교 분석
| 항목 | Sentry | SigNoz | Grafana LGTM Stack |
|---|---|---|---|
| OTLP Trace 지원 | ✅ 지원 | ✅ 지원 | ✅ 지원 |
| OTLP Metric 지원 | ❌ 미지원 | ✅ 지원 | ✅ 지원 |
| OTLP Log 지원 | ❌ 미지원 | ✅ 지원 | ✅ 지원 |
| Self-hosting 가능 여부 | ✅ 가능 (초기 구성 쉬움, 커스텀 필요) | ✅ 가능 (Kubernetes에 최적화) | ✅ 가능 (구성 요소 다수, 고도화 설정 가능) |
| 대규모 트래픽 대응 난이도 | 높음: Kafka, ClickHouse 등 확장 필요 | 중간: K8s 기반 수평 확장 용이 | 높음: 구성 요소별 확장 및 통합 운영 요구 |
| 확장 시 고려 요소 | Snuba, Kafka, ClickHouse, Relay 개별 스케일링 | OpenTelemetry Collector, ClickHouse | Loki/Tempo/Mimir 개별 확장, Grafana 최적화 |
SigNoz 선택 배경과 이유
OpenTelemetry 네이티브 지원 강점
SigNoz는 OpenTelemetry를 네이티브하게 지원하며, Trace, Metrics, Logs를 하나의 플랫폼에서 통합 제공하는 점이 큰 매력이었습니다. 기존 OpenTelemetry 계측과의 통합이 매우 용이했고, 코드 수정 없이 환경변수만으로 도입 가능하다는 점이 결정적 요인이었습니다.
ClickHouse 기반 단일 저장소의 이점
SigNoz는 로그, Metrics, 트레이스 데이터를 모두 단일 ClickHouse 저장소에 통합 저장합니다. 이는 LGTM 스택과 대비되는 장점입니다:
- LGTM 스택: Loki(로그), Mimir/Prometheus(Metrics), Tempo(트레이스) 등 데이터 유형별 별도 저장소로 관리 복잡성 증가
- SigNoz + ClickHouse: 모든 텔레메트리 데이터가 단일 ClickHouse에 저장
- 데이터 간 상관관계 분석 용이
- 백업 및 복구 단순화
- 단일 저장소 기술 학습으로 운영 부담 감소
- 스토리지 확장 시 한 번의 작업으로 처리 가능
ClickHouse의 확장성과 통합 저장소 방식은 미래 지향적인 모니터링 시스템 구축에 핵심 요소였습니다. 현재 단일 노드로 시작하더라도, 데이터 증가 시 클러스터로 확장할 경로가 명확합니다.
SigNoz의 단점은 레퍼런스가 적다는 점이었으나, 아키텍처 단순함과 기능적 완결성이 이를 상쇄한다고 판단했습니다.
설치 환경 선택
Compute Instance 선택 이유
Kubernetes와 Compute Instance(VM) 중 고민 끝에 Compute Instance를 선택한 이유는 다음과 같습니다:
- CSP의 Kubernetes 환경 신뢰도 부족 (스토리지 드라이버, CSI 플러그인 문제)
- 모니터링 시스템은 설치 후 자주 관리하지 않음
- VM 환경에서 볼륨 사용량 모니터링이 단순
- Kubernetes 설치 및 운용의 러닝 커브 고려
- VM 환경에서 백업 및 복원이 쉬움
스케일링 고려사항
스케일링 시나리오를 검토했습니다. 현재 서비스는 모니터링 시스템에 무중단이 필수적이지 않으며, 새벽 관리 시간은 허용 가능했습니다.
- 볼륨 스케일링:
- CSP에 따라 다름, 현재 VM은 오프라인 리사이징 가능
- 인스턴스 중지 → 볼륨 크기 수정 → 재시작
📝 참고: Kubernetes와 VM 모두 볼륨 확장 가능, VM은 오프라인 리사이징으로 중단 발생 가능
- 리소스 부족 상황:
- VM 스펙 조정으로 대응
운영
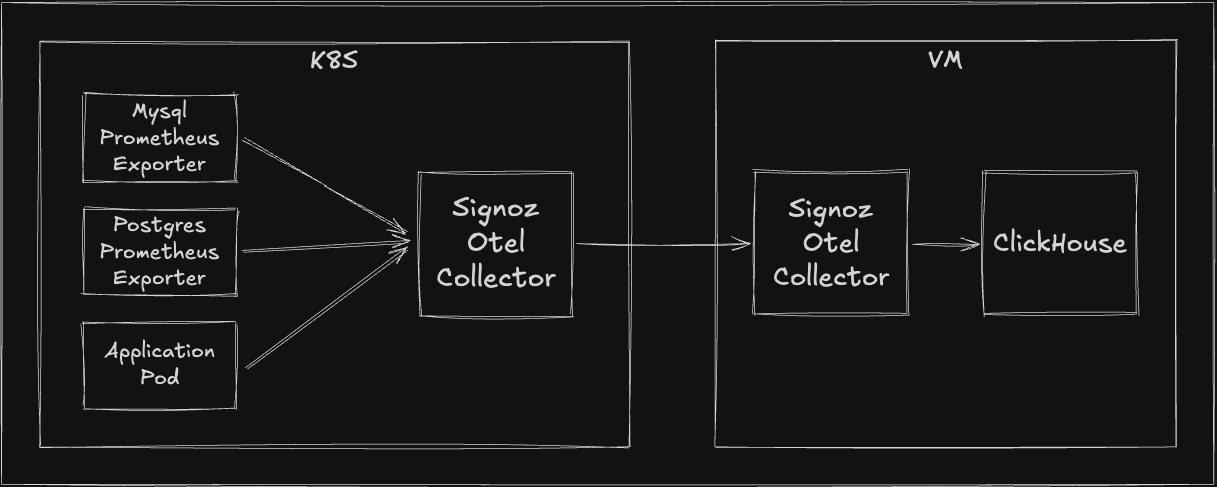
데이터베이스 Metrics 수집
Kubernetes에 Prometheus MySQL, PostgreSQL Exporter를 배포하고, OpenTelemetry Collector로 데이터를 수집하도록 설정했습니다. 이를 통해 SigNoz에서 데이터베이스 Metrics를 조회 가능하게 했습니다. 다만, 데이터베이스 OS Metrics는 아직 통합하지 못했으며, API 제공 여부 확인 후 통합 예정입니다.
주요 오류 및 해결 방법
- “Too many operations to track, using overflow operation name”
signozspanmetrics/delta에서max_services_to_track,max_operations_to_track_per_service값 증가
- “context deadline exceeded”
signozclickhousemetrics의timeout값 증가
- “logs 탭이나 traces 탭으로 이동시 EC2 다운되는 문제 ( 2025-04-09 추가 )
- 디스크 볼륨 주기적 모니터링:
- SigNoz VM의 OS Metrics 수집 및 디스크 사용량 알림 설정
- 기본 리텐션으로 볼륨 사이즈 안정화 가능
- OpenTelemetry Collector 로그 모니터링:
- Collector 로그 수집 설정 및 주기적 확인
- 과부하 시 데이터 누락 방지를 위해 로그 추적 필수
최신 업데이트 및 발전 방향
SigNoz는 지속적으로 발전 중이며, 0.76 버전에서 아키텍처가 단순화되었습니다. 관리 포인트가 줄어 운영이 더 쉬워졌습니다. GitHub - SigNoz/signoz: Release v0.76.0
다른 솔루션 대비 좋았던 부분
SigNoz 도입 후 Datadog과 비교 시 몇 가지 장점이 두드러졌습니다. Datadog은 다양한 기능을 제공하지만, 모든 기능을 활용하기 어렵고 UI 직관성이 부족했습니다. 반면, SigNoz는 직관적인 UI로 사용이 쉬웠습니다.
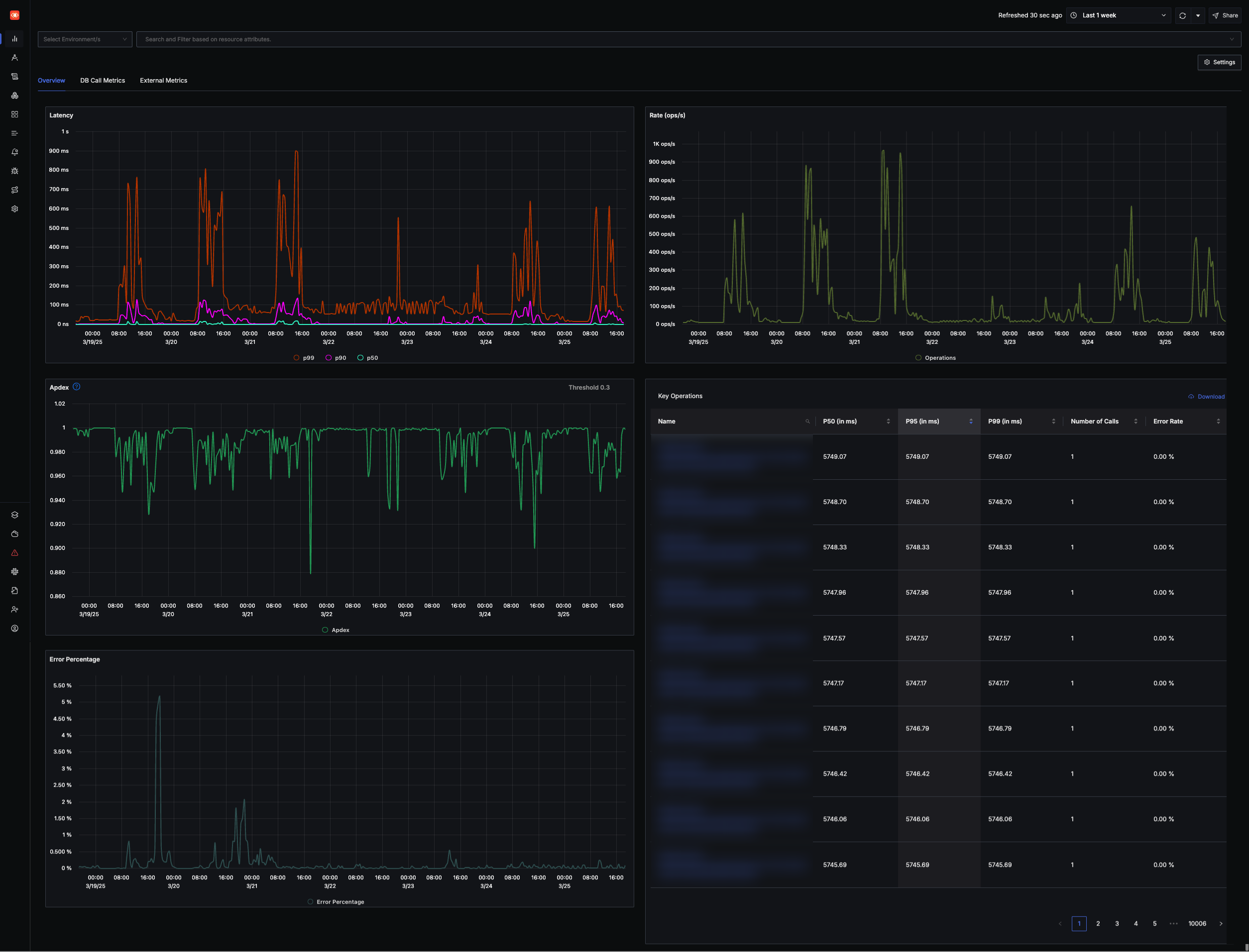
APM 기본 대시보드의 우수성
SigNoz는 APM(애플리케이션 성능 모니터링)을 위한 기본 대시보드를 별도 구성 없이 즉시 활용 가능하도록 설계했습니다. 서비스별, 오퍼레이션별 통계를 테이블로 제공하며, 기간별 데이터 조회가 빠르고 효율적입니다.

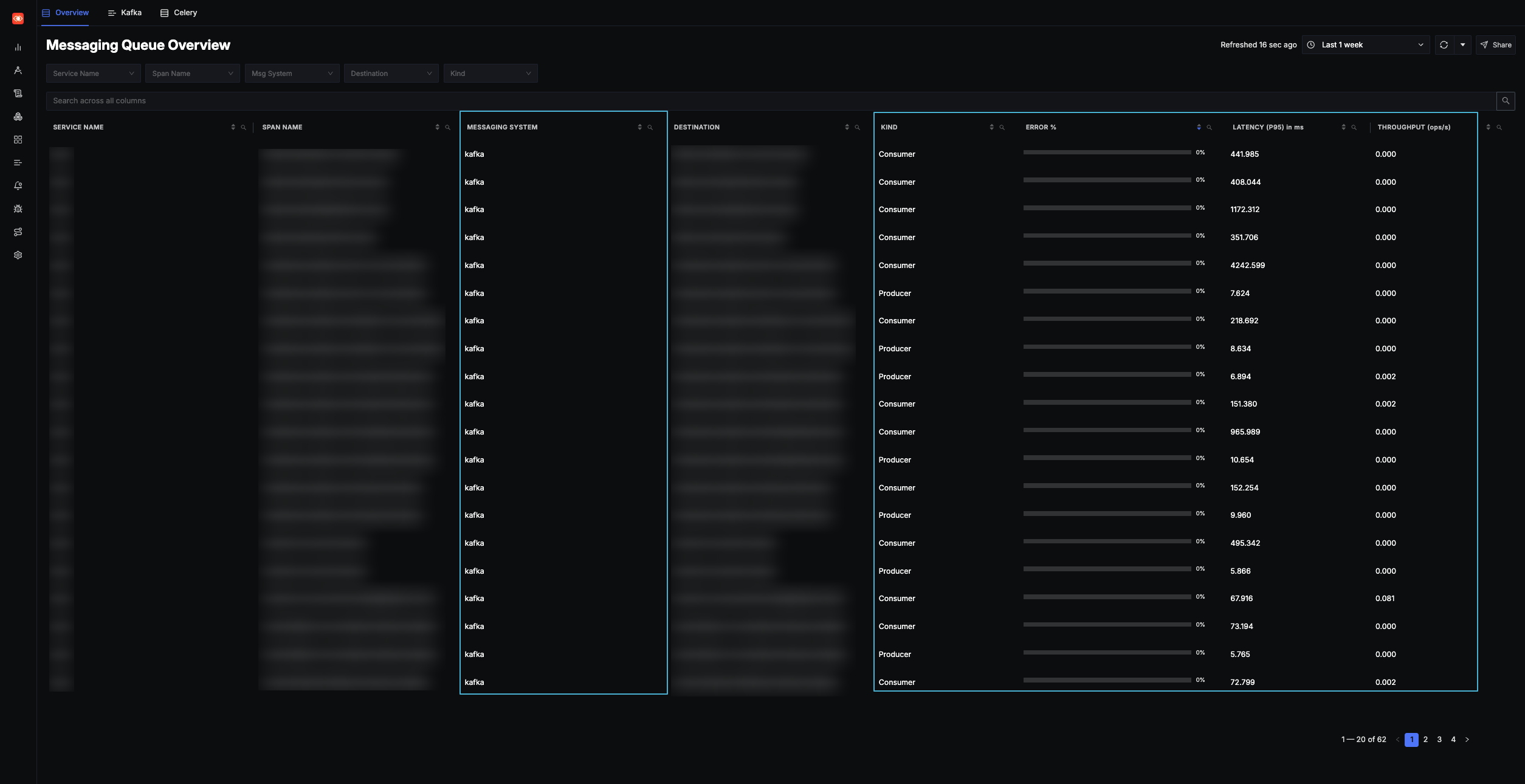
Messaging Queue 통합 모니터링
Kafka 같은 메시징 큐의 Instrumentation 활성화 시, SigNoz는 Span 데이터를 자동 분석해 전용 모니터링 대시보드를 제공합니다. 별도 설정 없이도 동작 상태를 시각화할 수 있어 편리했습니다.
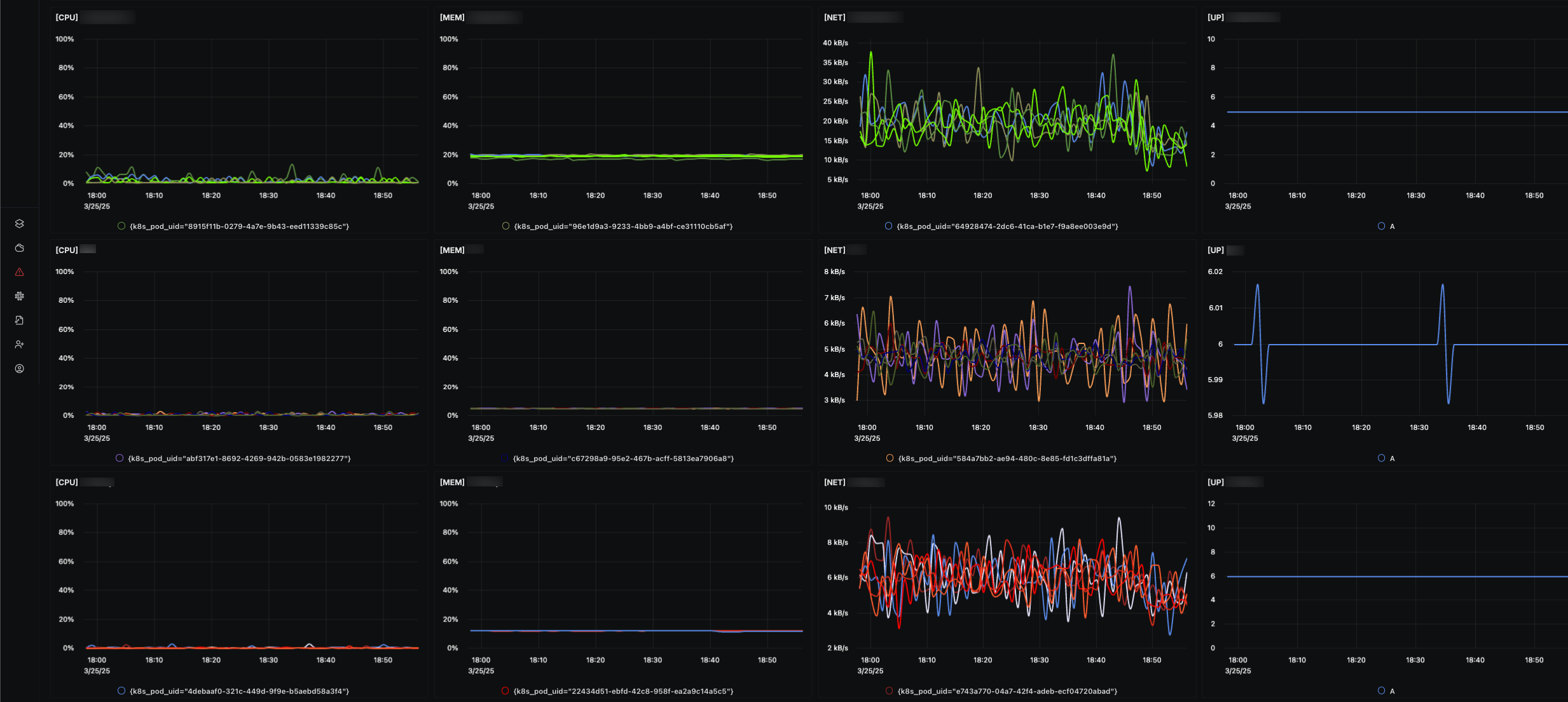
뛰어난 시각적 가시성
SigNoz의 UI는 높은 대비 색상과 명료한 레이아웃으로 뛰어난 가시성을 제공합니다. 직관적인 디자인 덕분에 정보 파악이 쉬웠습니다.
마무리
보안 제약 환경에서 OpenTelemetry를 활용해 SigNoz 기반 자체 모니터링 시스템을 구축한 과정을 살펴보았습니다. SigNoz 적용 결과, Datadog 대비 비용 효율성이 뛰어났고, 디스크 볼륨 사용량이 예상보다 안정적으로 유지되어 운영 부담이 적음을 확인했습니다.
이에 따라 기존 Datadog 시스템을 SigNoz로 전면 대체하기로 결정했으며, 성공 시 상당한 비용 절감이 예상됩니다. 이번 경험과 교훈이 유사 환경에서 자체 모니터링 시스템 도입을 검토하는 분들에게 실질적인 참고가 되기를 바랍니다.