멀티테넌시? 어떻게 설계하고 접근하지?
Intro
개발하다 보면 멀티테넌시(Multi-tenancy) 구조를 마주하게 됩니다. 초기 스타트업이나 비용 효율이 중요한 단계에서는 하나의 데이터베이스 인스턴스를 여러 고객(Tenant)이 공유하는 Shared Database, Shared Schema 패턴이 가장 합리적인 선택지입니다.
하지만 프로젝트가 DDD를 지향하고 있다면 여기서 딜레마가 발생합니다.
“모든 엔티티에 tenantId를 넣어야 하는가? 그렇다면 도메인 로직이 인프라스트럭처(격리 규칙)에 오염되는 것은 아닌가?”
이번 글에서는 공부하는 과정에서 테넌트 격리라는 물리적 제약을 극복하고, 도메인의 순수성을 지키면서도 안전하게 멀티테넌시에 접근하는 방법을 정리해보았습니다.
테넌트 격리 수준별 구현 종류
멀티테넌시를 적용할 때는 비즈니스 성장 단계와 요구사항에 따라 다양한 격리 수준을 선택할 수 있습니다.
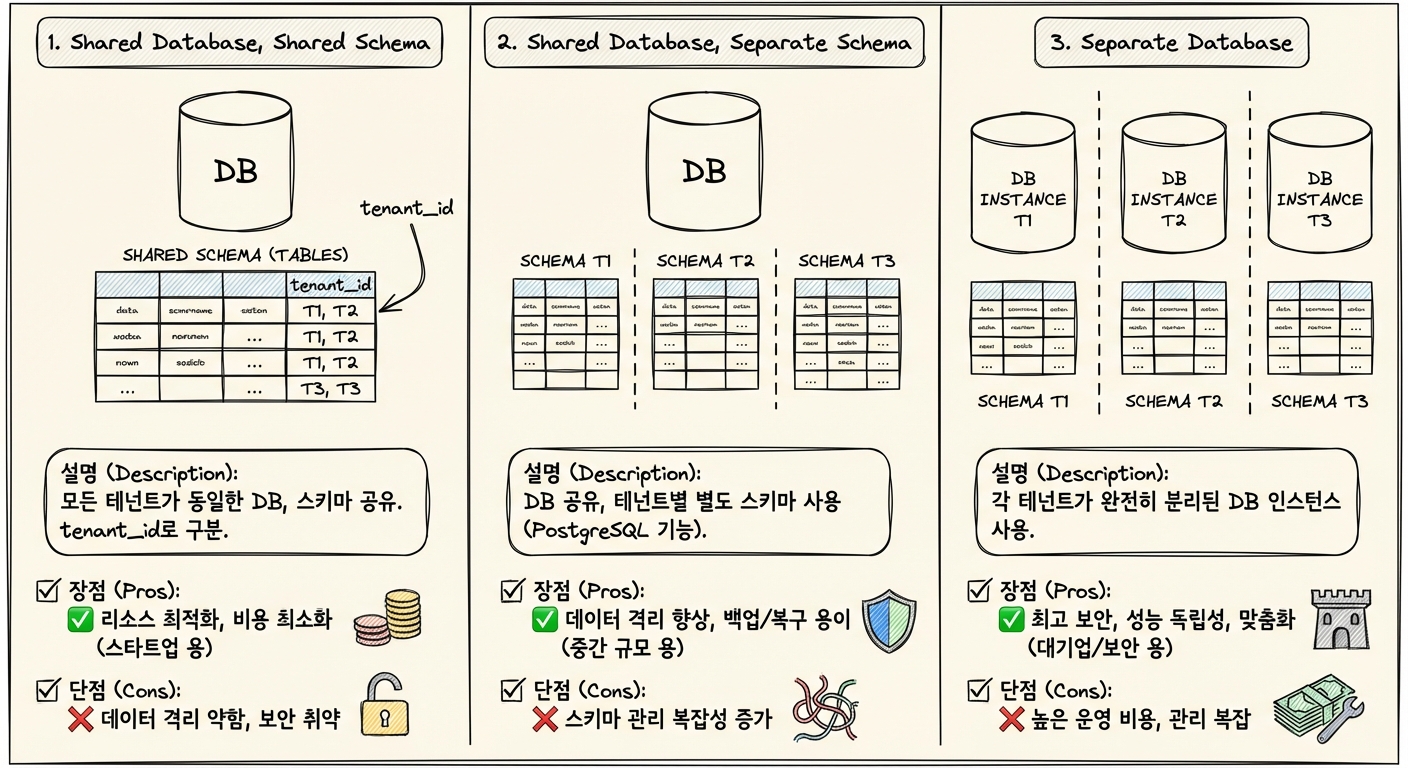
1. Shared Database, Shared Schema
- 설명: 모든 테넌트가 동일한 데이터베이스와 스키마(테이블)를 공유
- 특징:
- 가장 비용 효율적인 방식
tenant_id컬럼으로 데이터를 구분- 초기 스타트업이나 소규모 서비스에 적합
- 장점: 리소스 사용 최적화, 운영 비용 최소화
- 단점: 데이터 격리가 약하고, 보안 이슈에 취약
2. Shared Database, Separate Schema
- 설명: 데이터베이스는 공유하지만, 각 테넌트별로 별도 스키마를 사용
- 특징:
- PostgreSQL 스키마 기능 활용
- 테넌트별로 테이블이 분리되어 있음
- 중간 규모의 서비스에 적합
- 장점: 데이터 격리 수준 향상, 백업/복구 용이
- 단점: 스키마 관리 복잡성 증가
3. Separate Database
- 설명: 각 테넌트가 완전히 분리된 데이터베이스 인스턴스를 사용
- 특징:
- 가장 높은 수준의 데이터 격리
- 대기업이나 보안이 중요한 서비스에 적합
- 장점: 최고 수준의 보안, 성능 독립성, 맞춤화 용이
- 단점: 높은 운영 비용, 복잡한 관리
테넌트(Tenant)의 정의와 판단 기준
멀티테넌시에서 테넌트는 “데이터와 설정이 서로 격리되어야 하는 독립적인 논리적 단위”를 의미합니다. 보통 하나의 고객 회사(Organization), 기관, 또는 과금/계약 단위를 테넌트로 봅니다.
테넌트 여부 판단 체크리스트
- 데이터 격리가 필수적인가?: 해당 단위의 데이터가 타 단위와 완전히 분리되어야 한다면 테넌트입니다. 내부 공유 목적이라면 테넌트 내부의 ‘그룹/팀’으로 처리합니다.
- 과금 및 관리의 주체인가?: 독립된 요금 청구, 관리자 계정, 설정 값이 필요하다면 테넌트로 정의합니다.
- 보안 및 규제 준수 대상인가?: 법적·보안상 이유로 데이터 혼용이 금지된 단위라면 테넌트입니다.
실무 예시
- Slack/MS 365/Notion: 하나의 워크스페이스나 회사(Organization)가 테넌트입니다. 그 내부의 채널, 팀, 부서는 테넌트 내부의 권한(RBAC) 체계로 관리됩니다.
- 계층적(Hierarchical) 구조: 프랜차이즈처럼 본사가 하위 지사의 데이터를 관리해야 하는 경우, ‘본사(최상위 테넌트) - 지사(서브 테넌트)’ 형태의 계층적 멀티테넌시 구조를 설계하기도 합니다.
결론적으로, 대부분의 SaaS에서는 조직/기관/회사 = 테넌트이며, 내부의 그룹이나 팀은 테넌트 내의 하위 구조로 설계하는 것이 일반적입니다.
어떤 격리 수준을 선택해야 할까?
대부분의 서비스는 Shared Database, Shared Schema로 시작합니다. 비용 효율이 가장 중요하기 때문입니다.
하지만 이 선택이 단순히 인프라 결정으로 끝나지 않고, 애플리케이션 코드 설계에 큰 영향을 미치기 시작합니다.
이때 개발자들은 구현 단계에서 고민되는 지점이 생기고 실수를 할 수 있습니다. 바로 테넌트 격리라는 기술적 제약을 비즈니스 로직 안으로 끌어들이는 것입니다.
이제부터 이 문제가 왜 발생하는지, 그리고 어떻게 해결해야 하는지 살펴보겠습니다.
1. 문제 상황: 도메인 오염 (Domain Pollution)
초기 구현 시 가장 흔히 범하는 실수는 비즈니스 로직의 중심인 도메인 모델(Aggregate Root)에 테넌트 식별자를 강결합하는 것입니다.
흔히 보이는 패턴
- 모든 도메인 엔티티에
tenantId필드 추가 - Service 계층의 모든 메서드 파라미터로
tenantId를 전달 - 개발자가 쿼리를 작성할 때마다 수동으로
WHERE tenant_id = ?를 추가
그럼 나중에 물리적 DB 분리로의 전환은??
문제점은 다음과 같습니다.
- 비즈니스 로직의 혼탁함: 도메인 모델이 “데이터 격리”라는 인프라적 관심사에 의해 지저분해집니다
- 휴먼 에러 위험: 개발자가 실수로
tenantId필터링을 누락하면, A사의 데이터가 B사에게 노출되는 치명적인 보안 사고(Data Leakage)가 발생합니다 - 마이그레이션 비용: 추후 특정 대형 고객을 위해 물리적으로 DB를 분리(Separate DB)해야 할 때, 코드 전반에 퍼진
tenantId로직을 걷어내는 대공사가 필요합니다
2. 원인 분석: 테넌트는 “속성”인가 “컨텍스트”인가?
이 문제의 근본 원인은 테넌트 정보를 도메인 객체의 속성(Property)으로 보느냐, 실행 컨텍스트(Context)로 보느냐의 관점 차이에 있습니다.
- 속성으로 볼 때:
User.tenantId처럼 명시적이지만, 도메인이 특정 스키마 구조(Shared Schema)에 종속됩니다 - 컨텍스트로 볼 때: “누가 요청했는가”에 대한 환경 정보이므로, 도메인 로직은 이를 몰라도 됩니다. 인프라(Repository)가 알아서 처리하면 됩니다
우리는 후자(컨텍스트)를 선택해야 합니다. 그래야만 애플리케이션이 유연해집니다.
3. 해결 전략: 횡단 관심사로의 분리
도메인 모델을 순수하게 유지하기 위해, 테넌트 처리를 애플리케이션의 횡단 관심사(Cross-cutting Concern)로 분리하는 전략을 사용합니다.
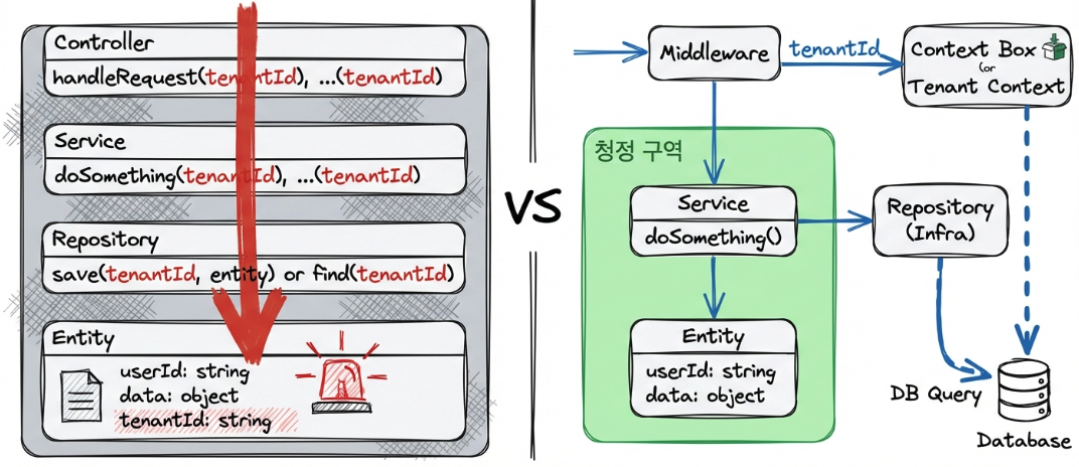
전략 1: 요청 스코프에 테넌트 컨텍스트 저장 (AsyncLocalStorage)
요청이 들어오는 진입점(Middleware/Guard/Interceptor)에서 테넌트를 식별하고, 해당 요청이 끝날 때까지 유지되는 저장소에 테넌트 ID를 보관합니다.
Node.js 환경(NestJS)에서는 AsyncLocalStorage(ALS)가 사실상의 표준입니다. 이는 Java의 ThreadLocal과 유사하게 비동기 흐름 내에서 상태를 공유할 수 있게 해줍니다.
전략 2: Repository 구현체에서의 의존성 주입
이 전략의 핵심입니다. 도메인 계층의 인터페이스(Repository Interface)는 테넌트를 모르게 하고, 인프라 계층의 구현체(Repository Implementation)에서만 컨텍스트에 접근합니다.
테넌트 식별 정보는 어떻게 전달하는가?
클라이언트가 요청을 보낼 때 테넌트를 식별하는 방식은 다양합니다. 주요 방식 3가지를 비교하면 다음과 같습니다.
| 방식 | 특징 | 장점 | 단점 |
|---|---|---|---|
| Custom Header | X-Tenant-ID 헤더 사용 | 구현이 단순하고 API 테스트가 용이함 | 클라이언트가 매 요청마다 헤더를 관리해야 함 |
| Subdomain | a.example.com 형태 | 테넌트별 독립 브랜딩 및 쿠키 격리 가능 | SSL 인증서 관리 및 DNS 설정 복잡성 증가 |
| JWT Claims | 토큰 내 tenantId 포함 | 보안이 가장 강력하며 B2B SaaS 표준 방식 | 로그인 전(인증 전) 단계에서는 식별 불가 |
서비스의 비즈니스 모델과 운영 복잡도를 고려하여 적절한 방식을 선택해야 합니다.
적용 방법 (NestJS + DDD 구조)
1. 테넌트 컨텍스트 및 미들웨어 (Entry Point)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// infrastructure/context/tenant.context.ts
import { AsyncLocalStorage } from 'async_hooks';
const storage = new AsyncLocalStorage<string>();
export const TenantContext = {
run: (tenantId: string, fn: () => void) => storage.run(tenantId, fn),
getTenantId: (): string | undefined => storage.getStore(),
};
// infrastructure/middleware/tenant.middleware.ts
@Injectable()
export class TenantMiddleware implements NestMiddleware {
use(req: Request, res: Response, next: NextFunction) {
const tenantId = req.headers['x-tenant-id'] as string;
if (!tenantId) throw new UnauthorizedException('Tenant missing');
// 이 스코프 안에서 실행되는 모든 비동기 호출은 tenantId를 공유함
TenantContext.run(tenantId, next);
}
}
2. Domain & Application Layer (테넌트 존재를 모름)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// domain/user.entity.ts
export class User {
constructor(public readonly id: string, private email: string) {}
changeEmail(newEmail: string) {
this.email = newEmail;
}
}
// application/user.service.ts
@Injectable()
export class UserService {
constructor(private readonly userRepo: IUserRepository) {}
async updateEmail(id: string, email: string) {
const user = await this.userRepo.findOne(id); // 테넌트 ID 파라미터가 없음!
user.changeEmail(email);
await this.userRepo.save(user);
}
}
3. Infrastructure Layer (자동 격리 구현)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
// infrastructure/persistence/user.repository.impl.ts
@Injectable()
export class TypeOrmUserRepository implements IUserRepository {
constructor(
@InjectRepository(UserOrmEntity)
private readonly repo: Repository<UserOrmEntity>,
) {}
async findOne(id: string): Promise<User> {
const tenantId = TenantContext.getTenantId();
// 인프라 계층에서만 tenantId를 사용하여 DB 레벨 격리 수행
const entity = await this.repo.findOne({ where: { id, tenantId } });
if (!entity) throw new NotFoundException();
return UserMapper.toDomain(entity);
}
async save(user: User): Promise<void> {
const tenantId = TenantContext.getTenantId();
const entity = UserMapper.toOrm(user, tenantId);
await this.repo.save(entity);
}
}
4. PostgreSQL RLS (Row Level Security)
애플리케이션 레벨에서의 격리는 훌륭하지만, 개발자가 실수할 여지는 여전히 존재합니다(예: Raw Query 사용 시).
이를 보완하기 위해 DB 레벨의 강제 격리를 권장합니다.
PostgreSQL의 RLS(Row Level Security) 기능을 사용하면, DB 세션 변수에 설정된 tenant_id와 일치하는 행만 조회되도록 강제할 수 있습니다. 이는 “Defense in Depth(심층 방어)” 전략의 일환으로, 애플리케이션이 뚫려도 데이터는 보호됩니다.
결론: 유연함과 안전함을 동시에
멀티테넌시 설계의 핵심은 테넌트 격리라는 ‘기술적 제약’이 비즈니스의 ‘본질적 로직’을 침범하지 않게 하는 것입니다.
- 테넌트를 속성이 아닌 컨텍스트로 취급하여 도메인 모델의 순수성을 지킵니다.
- AsyncLocalStorage와 레포지토리 패턴을 활용해 횡단 관심사를 인프라 계층으로 밀어냅니다.
- (선택) DB 레벨의 RLS를 통해 마지막 안전장치를 마련합니다.
이러한 접근은 초기 구현의 복잡성을 약간 높일 수 있지만, 장기적으로는 비즈니스 로직의 오염을 막고 추후 인프라 구조의 변화(Database 분리 등)에도 유연하게 대응할 수 있는 강력한 기반이 됩니다.
시스템은 견고하게, 코드는 유연하게 유지하는 것이 진정한 멀티테넌시 설계의 지향점이라고 생각합니다.